Last week two builders I genuinely respect — one from Anthropic, one from OpenAI — said the next step in AI engineering is loops: agents prompting agents to write code, mostly unattended, at whatever scale your budget allows. It's a compelling idea, it makes for a great demo, and it's partly right. I want to take it seriously, agree with the half that's true, and then talk about the half that gets quietly skipped — because that skipped half is the whole job.
Consider the source — kindly
This isn't a conspiracy take. It's just incentives, and incentives are worth naming out loud. Anthropic and OpenAI sell tokens. When the people who sell tokens tell you the new best practice is to run dramatically more token calls, that advice can be sincere and aligned with their revenue line at the same time. Both things are true.
So I've started treating foundation models the way I treat any other supplier: as a commodity input. Excellent, improving, increasingly interchangeable — and not the right party to define what “efficient” means for my product. Their roadmap optimizes tokens consumed. Mine has to optimize something else.
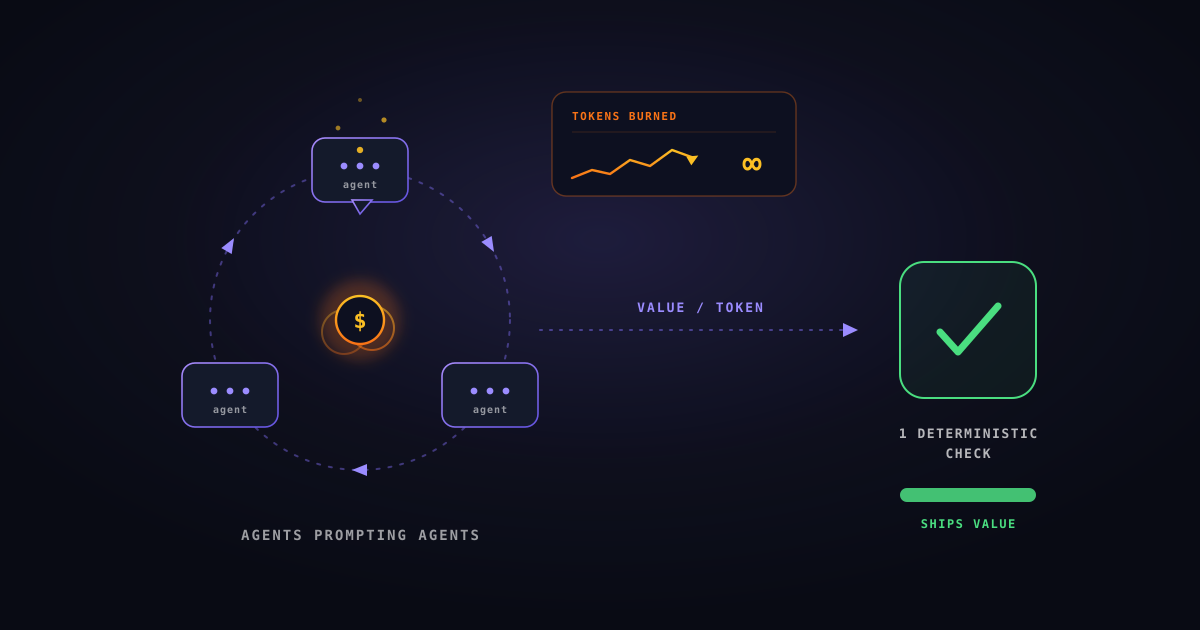
The goal isn't to maximize agent count. It's to maximize value delivered per token consumed.
The metric is value per token
More agents is not more progress. A workflow that fans out twenty agents to do the work of one is optimized for the screen-recording, not for your invoice or your codebase. The honest KPI — the one we put on our own dashboards — is value shipped per token spent. Once you hold that number in your head, a lot of the “just spin up more agents” advice stops looking like engineering and starts looking like a way to move the supplier's top-line metric on your dime.
This is not anti-AI, and it's definitely not anti-agent. We run agents all day. It's a question of what you point them at, and how you know when they're done.
Where loops genuinely shine
Let me steelman the other side, because there's a real case here. For a disciplined team — one that has already invested in mature agentic workflows, good specs, and tight feedback — loops are simply delivery at scale. If a feature costs $50–$100 in model calls instead of five to seven people for three or four weeks, the token bill is a rounding error. That math is real, and for teams operating at that level of discipline, “agents prompting agents” is a perfectly good way to ship.
So the loop isn't the villain. The trouble is what happens to everyone who isn't that team yet.
Where they quietly hurt
The failure mode isn't the disciplined team and it isn't the skeptic who refuses to touch agents. It's the large, fast-growing middle: teams who have half-adopted agentic engineering — a spec-driven setup installed, a few loops running — and start letting agents make load-bearing decisions blindly. System design drifts. Key architectural calls get made by a sampling loop instead of an engineer. And the team slowly loses the mental model of its own product.
That cost never shows up on the token bill. It shows up three months later, when something breaks and nobody on the team can explain how their own system actually works. The more code you generate without reading, the larger that debt grows — and a loop that prompts itself is very good at generating code nobody read.
The part a loop can't do: determinism
Here's the load-bearing point, and it's the one the hype skips. An LLM is a phenomenal human interface and a phenomenal code generator. Almost everything else that makes software trustworthy — state, control, and especially testing — needs to be deterministic.
Testing is the encoding of requirements and the articulated expectations of a product. You cannot reliably get that from the same stochastic loop that wrote the code, because a system that writes its own tests passes them by construction. The green checkmark means “it agreed with itself,” not “it's correct.” We wrote a whole post on why that's structurally true: You Can't Review Your Own Work.
And most of it doesn't need to burn tokens at all
A huge amount of the verification work — running the suite, diffing against expectations, exercising the public interface the way a user would, gating the merge — is deterministic and runs locally. It's cheap, repeatable, and doesn't get more correct because you spent more on inference. The model proposes; a deterministic harness disposes. That boundary is where reliability actually lives.
What we optimize for
This is the thesis QualityMax is built on, so I'll say it plainly: we're LLM-agnostic, provider-agnostic, and biased on quality. The model is a swappable, commodity input. The moat is the deterministic harness around it — the part that doesn't care which supplier won this week's benchmark.
- Cost-per-success, not tokens-per-feature. We route to the cheapest model that actually passes the gate, and measure ourselves on outcomes that shipped — not on how busy the agents looked.
- An independent verifier on every change. Generation and verification are separate jobs, run by separate systems, so the tests aren't graded by the thing that wrote them.
- A loop that compounds value, not spend. Every false positive you dismiss on a review becomes a durable, per-repo rule the next review retrieves automatically. The system gets smarter without getting more expensive — the exact opposite of a loop whose only growth axis is the token meter.
That's the distinction I care about. A slop loop grows the bill. A good system grows the verified knowledge and keeps the bill flat.
Burn less, ship more
So take the loop advice for what it's worth — useful in the right hands, oversold as a universal law, and conveniently aligned with the interests of the people selling the fuel. Use agents. Use a lot of them when the value-per-token math says so. But don't let a supplier define your efficiency target, don't let a loop become the place your team stops understanding its own system, and always keep one deterministic check between “generated” and “trusted.”
Fewer tokens. More value shipped. A real check in the middle. That's the whole game.
Put a deterministic check between generation and trust
QualityMax is the independent verifier on every PR — RAG-grounded test generation, a hollow-test gate, and multi-model routing that picks the cheapest model that passes. Model-agnostic by design, biased on quality.
Get Started Free