This is what status.anthropic.com looked like at 9pm CET today:
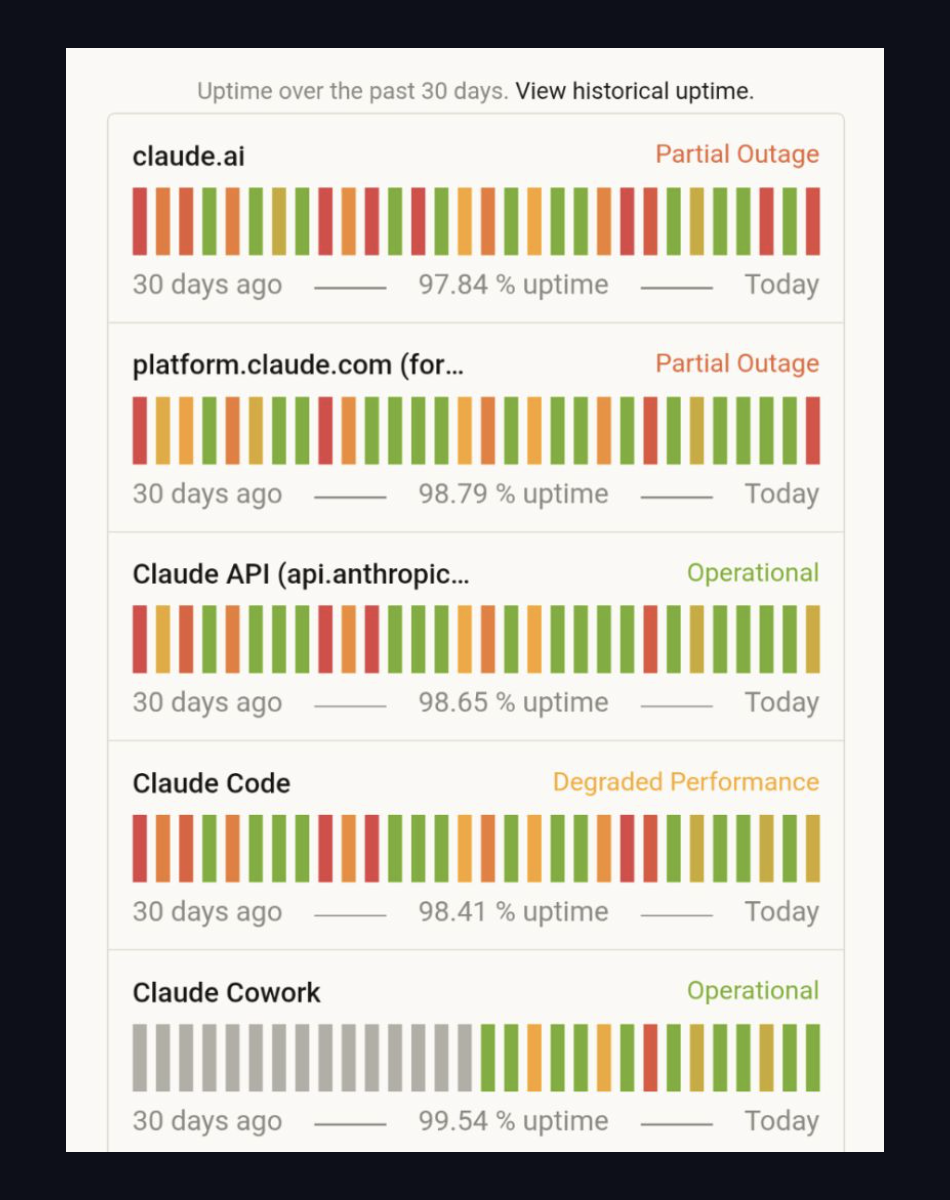
Two services in partial outage. Claude Code — the developer tool a meaningful fraction of engineers now ship from — degraded. Claude API itself wobbling around 98.6% uptime over the past month.
If you've built anything on top of Anthropic, today was a slow day. If you've built an AI test platform on top of Anthropic, today your customers' CI pipelines stalled, their PR reviews didn't post, their flaky tests didn't get diagnosed, and their new test generations queued forever.
That's the bet most AI testing tools made. We didn't.
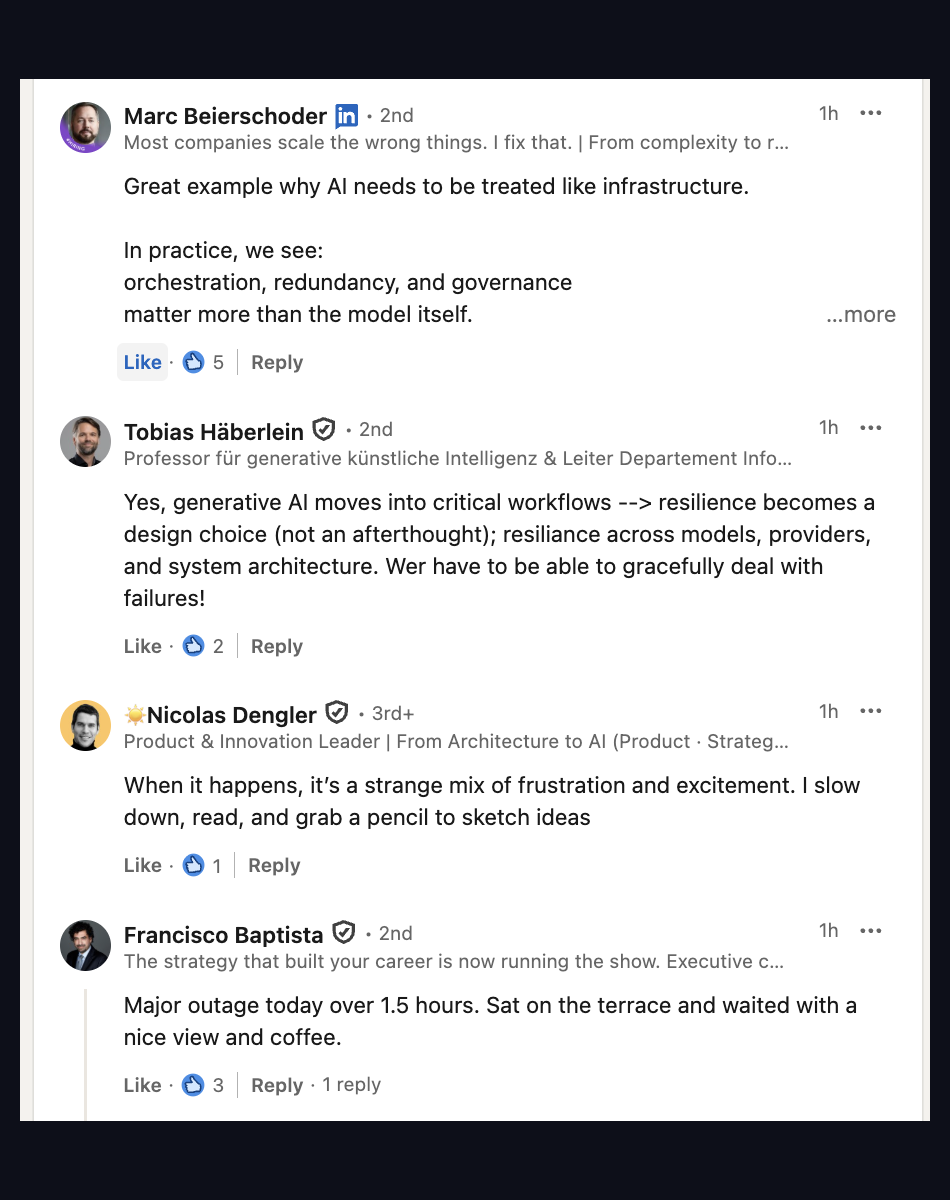
"Great example why AI needs to be treated like infrastructure. In practice, we see: orchestration, redundancy, and governance matter more than the model itself."
— Marc Beierschoder, on LinkedIn the morning after the outage
The hidden assumption in "AI-powered" anything
Pick any AI testing platform launched in 2024 or 2025. Read their docs. They'll tell you "powered by GPT-4" or "built on Claude" with the kind of pride normally reserved for a cool framework choice. What they don't tell you is the second sentence: your platform's uptime is now their model's uptime. Inherited, not negotiated.
For SaaS that wraps an LLM as a feature (chat, summarization, autocomplete), this is annoying but survivable — users wait, retry, move on. For an AI test platform sitting in your CI gate, it's worse: the gate either blocks merges (bad) or fails open (worse). Neither is what you signed up for when you put the platform in front of your release process.
The nature of LLM outages makes this acute. They aren't clean — one provider goes degraded for hours while another runs fine, then they swap. There's no failover to a backup data center because the data center's not the bottleneck; the model is. If your platform calls one model, you wait.
What we actually do
QualityMax routes work across Claude, GPT, and Gemini per task. Not "we have a fallback if our primary fails." Not "switch the global model in a config." Per-task routing, baked into the codebase. The decision is in services/ai_crawl/generation/model_router.py and looks roughly like this:
| Task | Primary | Fallback | Why |
|---|---|---|---|
| Crawl decisions | Claude Haiku | GPT-4o-mini | Speed and cost — thousands of calls per crawl. |
| Test generation | Claude Sonnet / Opus | GPT-4 / Gemini 2.5 | Deep code reasoning, framework-specific idioms. |
| Self-healing | Claude Sonnet | GPT-4o | Diff understanding, selector inference. |
| AI review | Claude Opus | GPT-4 / Gemini Pro | Long-context analysis of diffs and tests. |
| Adversarial eval | Configurable (BYOLLM) | — | Customer chooses which model judges their AI features. |
When Claude Code went degraded today, our test generation kept running on GPT-4. When the OpenAI API blipped two weeks ago, the same workflow flipped to Claude. Customers didn't notice either. That's the point.
Honest about the tradeoffs
Multi-model routing isn't free. It's mostly free, but not entirely. Three real costs we eat:
1. Behavior differences. The same prompt produces different output across providers. Claude tends to over-explain; GPT-4 tends to over-engineer; Gemini tends to be terser but less consistent on edge cases. We normalize via post-processing (strip preambles, validate schema, repair JSON) but it's real engineering work that a single-vendor platform skips.
2. Eval complexity. When a generated test fails in production, "which model wrote it?" matters for diagnosis. We tag every generation with provider + model + version in generation_metadata on the test record. Required for the dogfooding loop — you can't improve a prompt if you don't know which prompt-and-model produced the bad output.
3. Cost ceiling. Routing to "the best model for this task" can route you to the expensive one. We log every AI call to an ai_cost_log table and show per-day, per-user, per-model spend in our admin dashboard. Without that visibility, multi-model routing becomes a budget bonfire.
Worth it? Today's outage made the math obvious. The cost of an AI test platform being down for 4 hours during a release cycle — merges blocked or merges silently un-tested — is much higher than the prompt engineering tax.
The pitch in one line
If your AI test platform's status page mirrors a single LLM provider's, you don't have an AI test platform — you have a thin client.
What this means for you
If you're shopping AI test tools, the question isn't "which model do you use?" It's "which models, and what happens when one is down?" Most vendors will hedge or change the subject. The honest answer is a list of providers with fallback ordering and a recent outage anecdote where the fallback worked.
If you're already on QualityMax, today was a non-event by design. If you're on a single-vendor platform and today wasn't a non-event, you have your answer about the architecture you're paying for.
And if you're an engineer building anything else on top of an LLM — not just testing — copy this pattern. Per-task model routing is the cheapest insurance you'll ever buy.
Try QualityMax
AI test generation, self-healing, and PR-level evidence — routed across Claude, GPT, and Gemini so your CI doesn't go down when one provider does.
Get Started Free