Take a strip of paper. Give one end a half-twist. Glue the ends together. What you've made is called a Möbius strip, and it's unusual: it has only one side. Run your finger along the surface and you'll end up on "both sides" without ever crossing an edge. Inside and outside are the same place.
That's the shape of what we've been building at QualityMax.
This post is about the moment the QA tool and the thing it tests become one continuous surface — and why that only becomes possible once the tool owns the adjacent objects (the tests, the code, the errors, the AI).
Most QA tools are "outside in"
The standard shape of a QA stack is a stack of separate tools, each with a clear boundary.
- You have a test runner (Playwright, Cypress, pytest).
- You have an error tracker (Sentry, Datadog, Bugsink).
- You have a coding assistant (Cursor, Claude Code, Copilot).
- You have a CI system that glues some of them together with YAML and hope.
Each tool sits outside the code it touches. The error tracker sees the errors but not the tests. The test runner sees the tests but not the errors. The coding assistant writes the code but has no idea which tests cover it or which errors it's about to cause. The CI system sees the outputs but none of the context.
This architecture is fine. It also has a ceiling. When a production error fires at 3 AM, a human still has to walk the loop — read the stack trace in one tool, find the relevant test in another, open the file in a third, ask an AI in a fourth. The loop is there. It's just that you are the glue.
What happens when one tool owns the whole loop
QualityMax imports your repo. It crawls your app. It generates tests. It runs them in CI. It receives errors from production. It stores them. It knows which tests cover which files. It can call an AI with full context.
Those are all things other tools do. What's interesting is what happens when they're all in the same data model.
The instant the error tracker and the test database share a schema, the walk you used to do by hand becomes a JOIN. The instant the AI can read both the failing stack frame and the test that should have caught it, its suggestions stop being generic and start being specific to your codebase. The instant the same platform can open a PR with the fix, the loop closes without you touching a keyboard.
You go from four tools with four seams to one continuous surface. A Möbius strip.
The actual loop, in one diagram
No human glue. The tool owns every step.
The twist: QualityMax tests QualityMax
Here's where it gets weird.
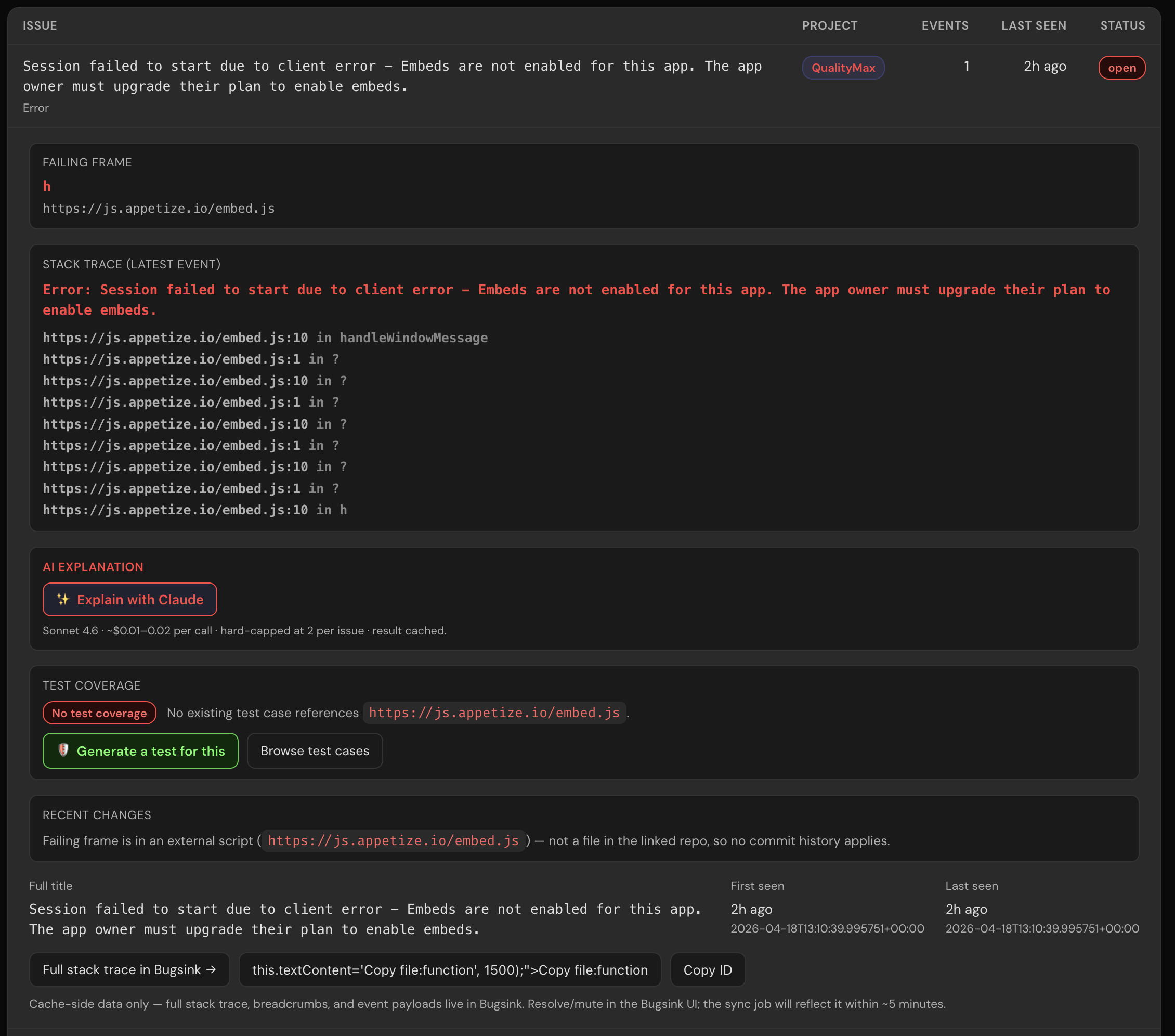
The QualityMax app is itself a codebase. That codebase has errors. Those errors get tracked in Bugsink. So we imported the QualityMax repository into QualityMax, linked our own Bugsink project to our own QM project, and let the loop run against us.
The first time I opened the embedded Bugsink page after the cross-link, the top issue was literally:
Failed to query Bugsink DB directly: connection to server at "localhost" (::1), port 15432 failed: Connection refused
That's our own MCP server, reporting its own inability to reach the old Bugsink endpoint — the exact bug the new cache architecture was built to eliminate. Bugsink tracking Bugsink's own obsolescence. The first user of the system was the system.
Why this is hard to copy
Any one of the pieces exists somewhere. Sentry owns the error side. GitHub owns the PR side. Cursor owns the code-authoring side. Playwright owns the test-execution side. But owning one of those is not the same as owning all four in one schema.
A standalone error tracker can never answer "which test should have caught this" because it doesn't know your tests. A coding assistant can never answer "which bug is this PR about to cause" because it doesn't know your error history. A CI platform can never propose a regression test because it doesn't own the test-authoring side.
To close the loop you have to have already imported the repo, generated tests, routed errors through your ingest, and kept the results in a shape that can be joined together. QualityMax has been doing that work as its primary job for a year. The Möbius loop isn't a new product — it's what you can see once the foundation is in place.
Concrete example: an Appetize timeout
Let me walk through one of the real issues on the dashboard right now so this isn't all metaphor.
Bugsink reports: [AppetizeBridge] Timed out waiting for session to be ready. 12 events in the last 24h. Stack frame: services/ai_crawl/mobile_discovery_crawler.py:start.
On the old architecture, that's where a human takes over. Open the file, figure out the timeout logic, check whether any test exercises mobile crawls, write a reproducer, open a PR.
On the new architecture, the loop does the walk:
- Linked project — the Bugsink project "QualityMax" is mapped to our QM project, which is mapped to the Quality-Max/qamax-rag-app repo. The file path resolves to a concrete repo location.
- Test coverage lookup — scan
automation_scripts.codefor the filename. Result: one integration test mentions the file, but it was last run three days ago and doesn't cover the ready-timeout path. - Recent changes — the last commit to touch
mobile_discovery_crawler.pywas PR #414. Opens in one click for reference. - Claude explain — the AI gets: the error title, the stack trace, the 50 lines around
start(), and the diff from PR #414. It explains that the ready-check uses a fixed 10-second timeout that's shorter than Appetize's cold-start under load, suggests a longer timeout with exponential backoff, and proposes a regression test that simulates a slow Appetize session. - PR drafted — the proposed test and patch are drafted back into the same repo. We review, tweak, merge. Bugsink's event count for this issue stops climbing.
That's the whole walk, end to end, on one platform. Not because the platform is magic — because the joins are possible.
What we're publishing today
The first cut of this is already live:
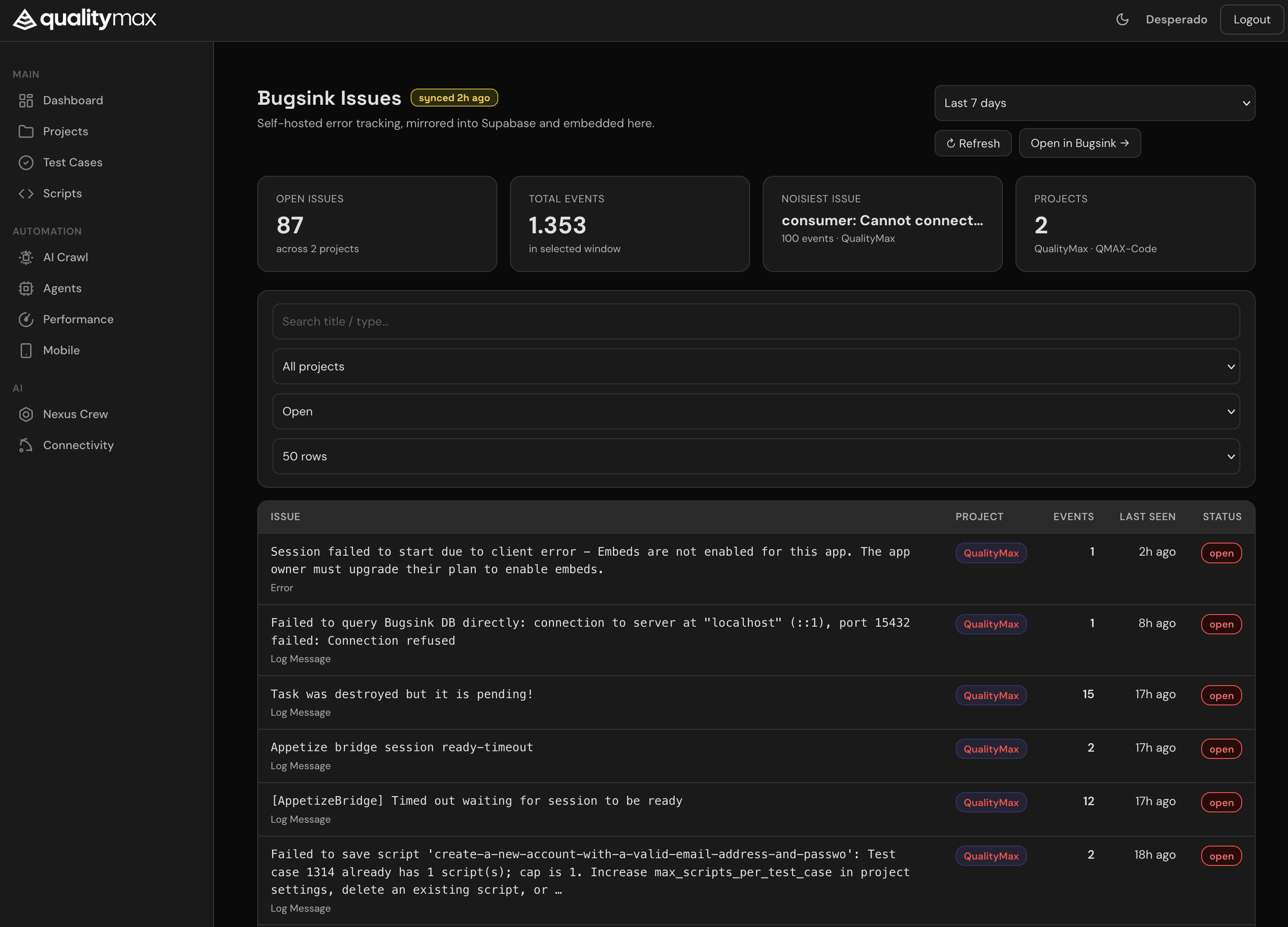
/bugsink page — Bugsink data living inside QualityMax, not as an external link.
- Bugsink embedded inside QualityMax at
/bugsink— filter, search, expand issues without leaving the app. Stack frames and failing files visible without a click-through. - Test-coverage linkage on every issue — "Covered by T-123" or "No test covers this file → Generate one".
- Supabase-mirrored cache so the error data is queryable with the same SQL as everything else in the platform.
- MCP tools (
bugsink_list_issues,bugsink_summary, etc.) so Claude Code and qmax-code can read production errors directly from the terminal, without a tunnel.
Still landing: "recent PRs that touched this file", Claude explain-this-error with source context, and auto-drafted regression tests. Each is a small amount of code on top of the join, because the join is the hard part.
The shape of the next decade of dev tools
Tools that sit outside the codebase are good at showing problems. Tools that sit inside — that own the errors, the tests, and the AI in one schema — are the ones that can close loops.
The metaphor of the Möbius strip isn't a clever framing. It's a description of the shape. One surface. One boundary. No more hand-off between the tool and the thing it tests, because they're the same surface traced continuously.
If you're building a product and you're tired of the standard four-tool, four-seam, human-is-the-glue architecture, come try ours. We built it the way we wish we had it — and now it monitors itself.
Try it on your repo
Import your codebase, connect Bugsink (or bring your own Sentry), watch the loop run against your own production errors.
Get Started →